文本标注
如果有兴趣,可以跟我联系交流:这里
[toc]
我们知道,在机器学习-监督学习的项目中,数据标注是一项很重要的数据前处理工作。比如图像识别,语音识别,自然语言处理项目中,都有各自需要标注的数据。
根据Cognilytica公司的一项统计,数据标注的工作量占到了整个项目的25%之多,跟数据清洗的25%加在一起就是50%了,也就是说,技术含量不算高但是劳动密集型的工作居然就占了一个机器学习项目的一半的工作量。
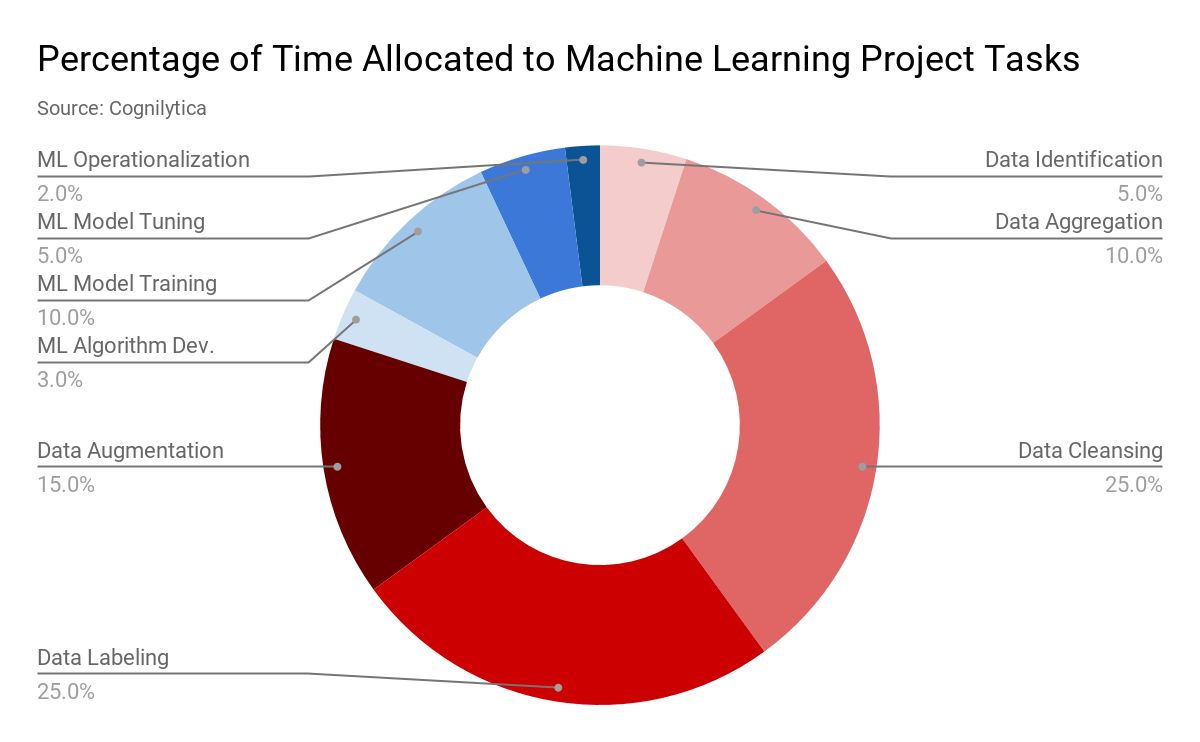
我们先不去纠结这些个数据到底有多准,从我们平时自己的工作内容里也可以印证,这部分工作量确实不少。
最近自己在做自然语言处理的项目,所以这里聊一下文本标注(text labeling)相关的东西。
各种标注方式的比较
这里先借用altexsoft的一张图
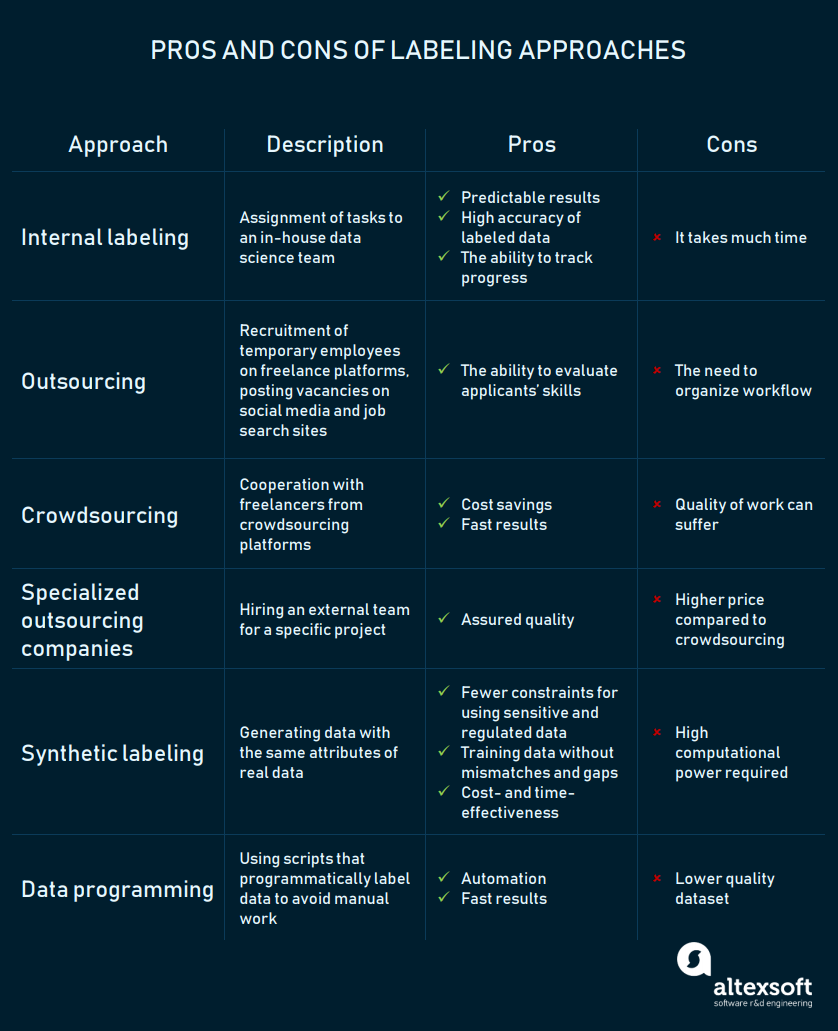
Internal labeling
就是谁要用数据就自己标注。
该方案的优点是:标注后的数据质量非常高,而且进度更加容易控制。
缺点是:人力少,标注速度很慢,而且对这些数据专家来说也是个消磨工作热情的过程。
crowdsourcing
就是利用Amazon Mechanical Turk (MTurk) 和 Clickworker这种众包平台找人来给你做数据标注。
优点是:对于只需要利用人的常识就可以做标注的活,很容易找到人来为你干,因为人多,所以干起来速度也会比较快。另外,价格是你自己订的,成本可控。
缺点是:标注质量不可控。因为标注者的常识水平不一,文化传统不一,对任务的理解能力也有差别,最后标出来的数据质量也会不一样。所以需要采取一些手段来减少或者避免这些问题。常用的方法有:
- 给出明确的说明书,阐明正确的做法和错误的做法
- 给出一个测试数据集,要求对方标完后进行考核,通过后才能参与正式的标注工作
- 对标注完的数据进行二次校验,将对方收入跟校验结果挂钩
outsourcing
就是大家常说的外包,外包分为“外包给个体”和“外包给公司”。
外包给个体就是,你通过社交媒体或者自己熟悉的渠道找到你认为符合某些技能的人,然后给他们写说明书告知他们流程,并且给他们分解任务。
优点是:你非常清楚你该雇什么样的人来做事,数据的质量可以得到更高的保障,并且你的沟通管理成本应该会比众包模式要小很多,二次校验的工作量也会小一些。
缺点是:你得自己花精力去找到你想找的那批人,然后得建立起一个好的工作流来让大家合作,这里可能会需要用到一些IT工具来辅助。
外包给公司,就很好理解了,就是行业里存在一些专业的做数据标注的公司,他们负责雇佣人员,培训人员,提供标注工具,你只要把你的需求和数据交付给他们,他们最终就给你交付一份你要的结果。有些公司很专业,比如专门就做图像标注,有的就干情感分析,有的图像标注和文本标注等全都接。这种公司有 CloudFactory, Mighty AI, LQA, DataPure, CrowdFlower, CapeStart,国内的公司不太了解。
优点是:标注数据的质量高,自己操心的比前几个方法要少很多。
缺点是:操心少,但是花的钱就要更多。
synthetic labeling
用一些已知的数据来训练模型,然后用模型来产生数据。有三种模型:Generative Adversarial Networks (or GANs), Autoregressive models (ARs), and Variational Autoencoders (VAEs). 这3个模型我本人也不怎么懂,大概来说,优点有:省钱省时间,而且不用担心数据的授权问题。缺点有:需要大量的计算资源,并且数据质量无法保障。
data programming
就是写程序去标注,这是个比较理想的方法,优点是:少了很多的人工介入,人力成本会少很多,但是缺点是:标注数据质量会很低。
文本标注工具
标注工具有免费的,也有收费的。
单机工具:Stanford CoreNLP
web工具:
常见错误和规避方法
我们已经知道,通过标注数据让我们得到了进行机器学习的基础训练集,我们要用它训练得到的模型去预测新的数据,那如果这个基础训练集的数据质量有问题,那后面的预测结果就可想而知了。
所以,我们可以设定一些基本的原则
- 要求标注数据的人有差不多的行业背景知识
- 做好数据标注指导手册,可以避免掉很多低级错误
- 多次定期评审标注上来的数据的质量,即使发现问题和纠正
- 指导手册不可能覆盖错有的情况,所以有些标准得在磨合中持续建立,然后在团队内达成一致
- 标注之前尽可能考虑完全了再开工,否则会有不断的返工流程
还有一些更加细节的注意事项
- 注意 标点符号,空格,大小写,规则要统一
- 有些场景下标注数据的顺序也很重要,要保持原本的顺序
- 要进行标注的label先整理完全了再开工,否则会出现这种情况:干了一半,发现缺少某个label,然后要求新加label,于是之前已经标注过的数据还要翻出来重新标注一遍。当然,这种情况可能无法完全避免,但是事前尽量考虑全一些总是可以减少一些问题
- label不要过多,否则选择label就是个很麻烦的事,不仅降低效率,而且还容易选错label,label数量少而精是我们追求的。