Graphite Project 调研
Contact me

或者用邮件交流 jacky.wucheng@foxmail.com
介绍
Graphite Project:
- Graphite-Web, a Django-based web application that
renders graphs and dashboardsusingCairo. - The Carbon, metric processing daemons based on
Twisted. Carbon is responsible forreceivingmetrics over the network,cachingthem in memory for “hot queries” from the Graphite-Web application, andpersistingthem to disk using the Whispertime-serieslibrary. - The Whisper, time-series
database library. - Ceres, Distributable time-series database
Graphite只做两件事
- Store numeric time-series data
- Render graphs of this data on demand
Graphite不采集metric, 需要靠其他工具采集. 参考 这里
Graphite WebUI
- douban graph-index
- Grafana - An open source, feature rich metrics dashboard and graph editor for Graphite, InfluxDB & OpenTSDB.
架构
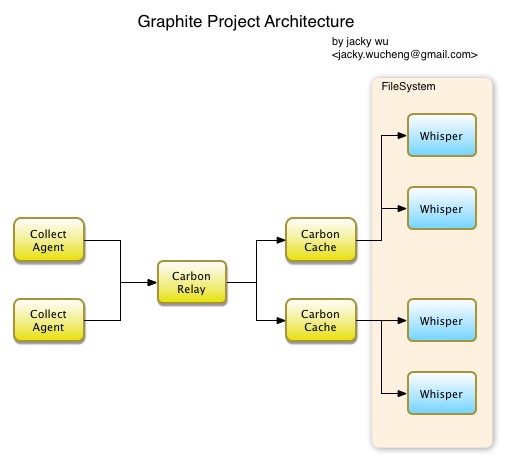

安装和配置
文档
配置
- 配置
/opt/graphite/webapp/graphite/local_settings.py, 参考 这里
如下的安装步骤都是从源码安装, 参考了 该文档
Carbon
安装
安装步骤
- git clone https://github.com/graphite-project/carbon.git
- python setup.py install
备注
- 安装路径: /opt/graphite/
- carbon监听2003端口, 接收数据, 但是不返回.
数据结构
数据点(datapoint)是包含如下信息的三元组:
- 指标项名称 metric
- 度量值 value
- 时间序列上某个特定的点(通常是一个时间戳) timestamp
客户端上报数据的协议
- 通过像netcat(nc)命令这样的工具,使用平文本协议发布
- 使用pickle协议
- 使用高级消息队列协议(AMQP)
- 用函数库,如Dropwizard Metrics库
Carbon Daemon
参考这里
Carbon包含了若干个Daemon, 每个Daemon都可以监听端口, 接受time-series数据.
- carbon-cache.py
- 接收incoming metric, 缓存在内存里, 然后每个interval flush到磁盘上wsp文件里.
- 如果carbon-cache io性能不够, 可以跑多个instance, 放到carbon-aggregator.py or carbon-relay.py后面.
- carbon-relay.py
- 转发给多个carbon-cache实例, 这些实例可以在不同机器的不同端口
- sharding. 按照一致性hash的规则转发读和写请求给多个carbon-cache实例, 分散压力.
- carbon-aggregator.py
- 放在carbon-cache前端, 接受incoming metric, 定期interval聚合, 然后写到后端的carbon-cache.
- 这个特点, 对于不按照固定interval汇报数据的场景很有用.
- 聚合的方法只有 sum和average.
carbon-aggregator和statsD的异同
参考这里
相同点
- 都可以监听udp, 应用程序可以不用等待tcp类似的延时. 解耦了.
- 都有很丰富的客户端.
不同点
- statsD支持采样sample, carbon-aggregator不支持.
- StatsD supports different metric types by adding extra aggregate values (e.g. for timers: mean, lower, upper and upper Xth percentile, …).
- statsD是node.js实现的, 性能更高.
- statsD和carbon-aggregator的聚合维度不一样. statsD是将同一个metric的多个值聚合成一个值. carbon-aggregator是将不同metric聚合成另一个metric.
- statsd supports rate calculation and summation but does not support averaging values
- carbon aggregator supports averaging but does not support rate calculation.
备注:
- statsD的python实现bucky
- Graphite’s minimum resolution is 1 second, statsD’s is 10 seconds.
Whisper
安装步骤
- git clone https://github.com/graphite-project/whisper.git
- python setup.py install
备注
- 安装路径: /usr/bin/
工具
- whisper-info.py
- whisper-dump.py
概念
- 存储区(Bucket), 等同于wsp文件中的archive
- 保留期(retention)
- xFilesFactor: 表示为了保证聚合准确,一个存储区必须包含的数据点比率。xFilesFactor设置为0到1之间的任意值。值0表示即使只有一个有效数据点,就会执行聚合。值1则表示只有全部的数据点都有效,才会执行聚合。
carbon控制whisper的配置文件
- /opt/graphite/conf/storage-schemas.conf
- /opt/graphite/conf/storage-aggregation.conf
Data Point
- timestamp
- float value
Archives: Retention and Precision
- 精度细的, 保留时间段短
- 精度粗的, 保留时间段长
- 高精度的需要跟低精度的, 有整除关系
聚合方法
- average
- sum
- last
- max
- min
Multi-Archive Storage和查询策略
- 数据写入的时候会同时写到多个archive. 最高的精度的archive会以原始数据直接写入, 其他精度的archive会对原始数据聚合后写入.
- 如果对最高精度的archive也要聚合, 可以使用 carbon-aggregator
whisper对磁盘空间的使用效率
总体来讲对磁盘空间使用效率并不是最有高效的, 原因有
- 每个value都存了一个绝对的timestamp, 并没有使用相对值.
- 低精度和高精度的archive, 需要好好设计
保留时间, 避免数据冗余存储.- 每一个time-slot都占用空间, 即使该timestamp没有值, 也占了空间.
whisper和rrd的区别
- rrd不能update当前之间之前的数据, 对于补数据的场景, rrd就无法适用
- 对于不规则的update, rrd会丢数据
- whipser要求数据按照固定的interval持续写入, 一旦受到一个数据, whisper会立刻写入. 而rrd是将收到的数据在临时区域先保存, 每个interval的时候进行聚合, 然后再写入rrd文件. 这就要求, 使用者自己掌控好写入的时间.
性能
- 比rrd慢大概2-4倍.
Ceres
Graphite-Project新开发的time-series数据库, 想要替换到whisper. 不过目前从github commit log上看进展缓慢.
Graphite-Web
安装步骤
- 使用python2.7 + virtualenv
- git clone https://github.com/graphite-project/graphite-web.git
- 检查各种依赖: python check-dependencies.py
- 安装依赖
- python setup.py install
- 数据库初始化: django-admin.py syncdb –settings=graphite.settings
- 创建配置: /opt/graphite/webapp/graphite/local_settings.py
- 启动:
cd /opt/graphite PYTHONPATH=`pwd`/storage/whisper ./bin/run-graphite-devel-server.py --port=8085 --libs=`pwd`/webapp /opt/graphite 1>/opt/graphite/storage/log/webapp/process.log 2>&1 &
备注
- 安装路径: /opt/graphite/webapp
问题解决方法
- python2.6不兼容django-1.7和以上的版本, 需要用1.6的版本. 参考 这里, 或者使用 python-2.7 ;
- pycairo无法安装, 解决办法: pip install pycairo –allow-external pycairo –allow-unverified pycairo
- Error loading either pysqlite2 or sqlite3 modules:
重新编译python2.7, 或者cp /usr/lib64/python2.6/lib-dynload/_sqlite3.so /usr/local/lib/python2.7/sqlite3/, 参考 这里 和 这里
登陆方法
root, 密码就是django syncdb时提示让设置的密码.
Graphite-Web Render API
- target: 要渲染的metric, 一个或者多个. 可以直接对target使用function
- path: 例如
servers.ix02ehssvc04v.cpu.total.user, 可以使用星号, 一个星号只能表示一个分节, Therefore,servers.*will not matchservers.ix02ehssvc04v.cpu.total.user, whileservers.*.*.*.*will. - template
- 输出格式
- 配置文件里的自定义参数列表
Function
非常丰富的函数, 参考 http://graphite.readthedocs.org/en/latest/functions.html , 函数代码在
graphite-web/webapp/graphite/render/functions.py里. Function只利用已有的数据通过算法计算出结果, 但是不会去判断是否有异常.
Graphite API的本质是, 利用如下模式对数据进行查询
- 操作对象 target
- 时间跨度 from, until
- 操作函数 function
缺点
- 数据量大了之后, whisper会产生很多文件, 影响磁盘io
- python的gil不能充分利用多核, 需要用多实例来规避, 带来了部署的复杂度
扩展方法
- 在服务器上启动多个carbon instance在不同端口, 用haproxy做反向代理.
FAQ
参考资料
- DevOps实战:Graphite监控上手指南, 包含了概念解释, 安装配置
- Graphite Tools
- 使用python构建基于opentsdb的metric监控客户端
- opentsdb -> 底层hbase, 架构图
- Influxdb 时序数据库, golang, 底层数据存数用的是leveldb或者是rocksdb
- ganglia
- rrdtool, 可以预先聚合, 提高mean效率, 缺点是不方便做分布式
- 使用grafana和Diamond构建Graphite监控系统
- 豆瓣的graph-index, 提供监控服务器的状态的目录索引,基于graph-explorer
- 用graphite diamond做监控
- 使用 Grafana+collectd+InfluxDB 打造现代监控系统
{kind=link}